
サイトで使われている画像を一括でダウンロードする方法です。
運営している無料ブログから自分の画像を取得したいときに重宝するかと思います。
 はにわまん
はにわまんいろんなソフトウェアを駆使しながらダウンロードしていきます
「Screaming Frog SEO Spider」でサイトの全ページ情報を取得
「Screaming Frog SEO Spider」を使って、サイトの全情報を取得します。
とても優秀なスクレイピングツールで、現時点でおそらくNo.1の品質です。
試しに、livedoor Blogの情報を取得してみようと思います。上のURLにサイトのトップページURLを入力して「Start」ボタンをクリック。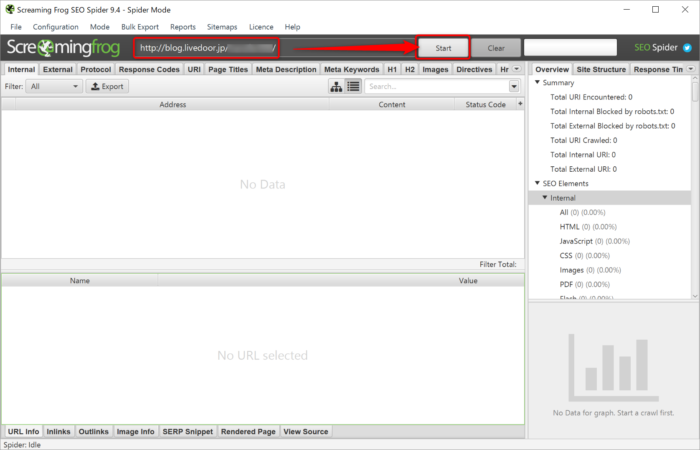
ずらーっとURLが取得されます。必要なのは画像のURLです。「Images」タブを開き、「Export」ボタンを押してcsvファイルをダウンロードしてください。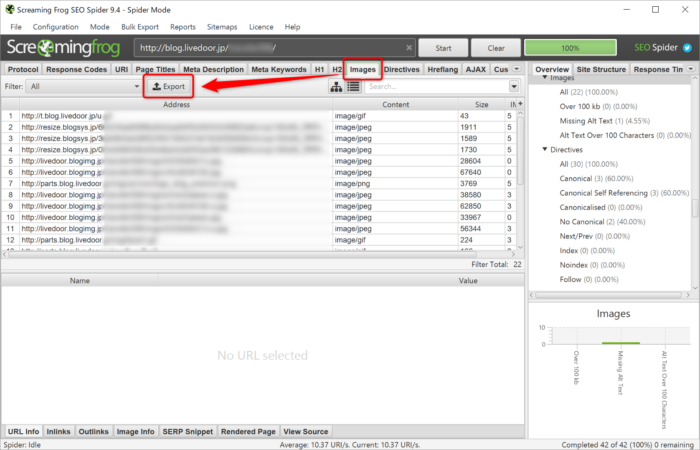
images_all.csvが保存されます。
Excelで開いてください(※ フィルターをかけるために)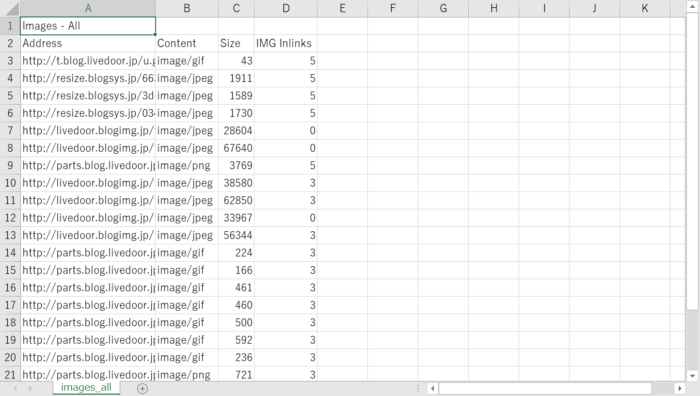
不要な画像も混ざっているので、必要なものだけに絞り込みします。必要なものは記事内の画像だけです。どういうURL構造になっているかデベロッパーツールなどで確認するといいでしょう。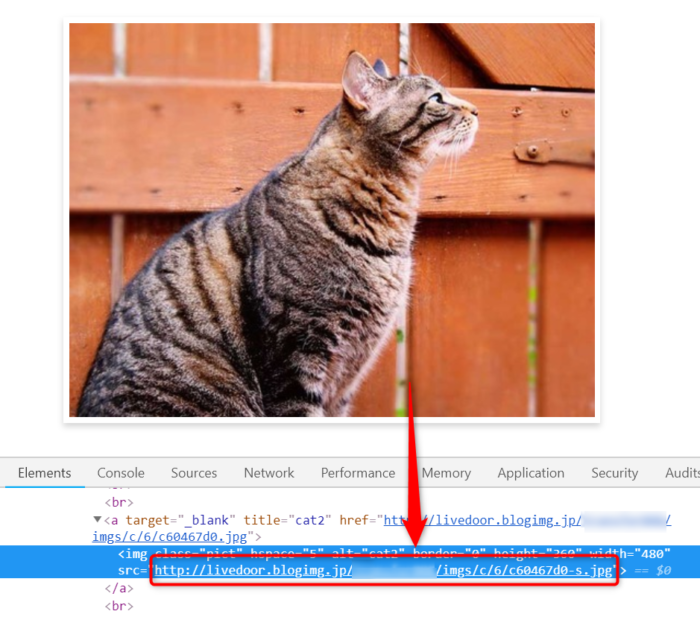
livedoor Blogなら「http://livedoor.blogimg.jp/」から始まるもので絞り込めば、記事内の自分の画像だけが取得できそうです。
「Address」選択して、Ctrl + Shift + Lでフィルターを付けます。
▽矢印をクリック(Alt + ↓)して、「テキストフィルター」→ 「指定の値で始める」→ Addressに「http://livedoor.blogimg.jp/」と入力して「OK」します。
※ 一連の流れをgifにしました。
フィルターして抽出された画像のURLをコピーしてテキストエディタで保存してください。ファイル名はなんでも大丈夫です。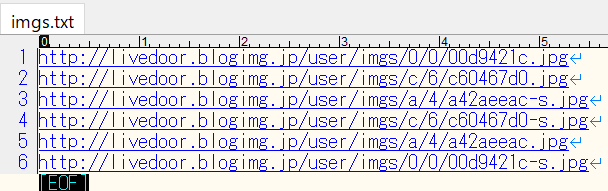
「Irvine」で画像URLから一括保存
Frogで画像URLを抽出しました。次に「Irvine」を使って画像URLから一括で保存します。
画像を保存するようのフォルダを1つ作っておいてください。そこに、先ほど作成した画像URL一覧のテキストファイルを格納します。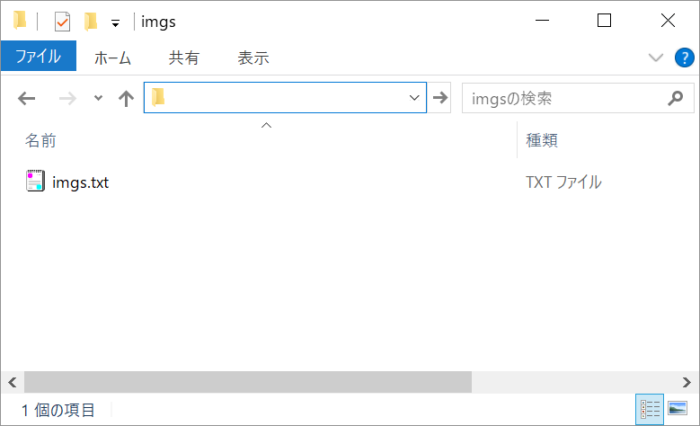
「Irvine」を起動して、ファイル → 新規作成 から
- キーフォルダ名 → 任意
- 保存フォルダ → 先ほど作成した保存用フォルダ
を作成します。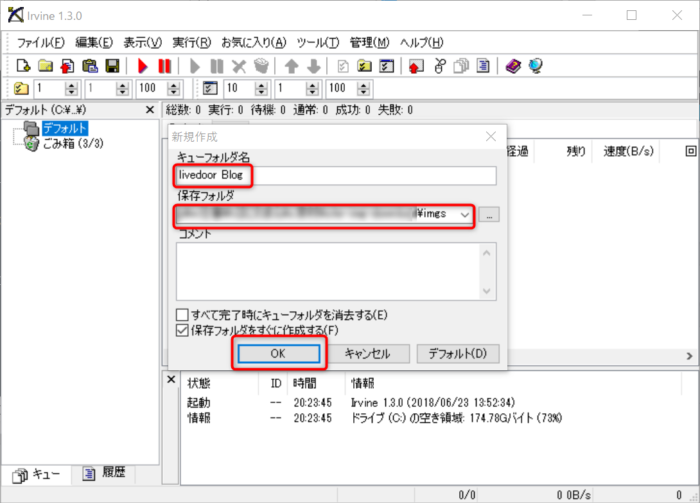
サイドメニューにある作成したキーフォルダを選択した状態で、ファイル → インポート → 自動インポート → 〇〇.txt
とすると、画像URLがすべて読み込まれ自動でダウンロードがスタートします。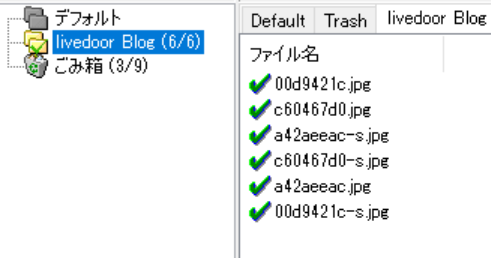
チェックがついていれば、成功です。指定したフォルダに画像が格納されています!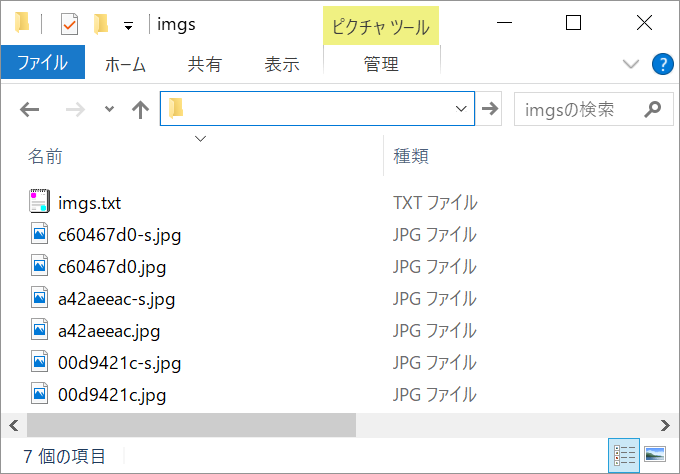
おわり
サイトで使われている画像を一括でダウンロードする方法でした!
2つのツールを横断するので、ちょっと手間はかかるかもしれません。1つでできるなら最高ですけどね。URLの一覧取得できるならwgetなどのUNIXコマンドからダウンロードできるので、使える方は「Irvine」のツールは不要かもしれません。
個人的には、無料ブロクから引っ越しする際に重宝するやり方だと思います。









